So I’m learning a lot of web development tools right now, with Learn Verified. It’s awesome. I love programming, and I love using Ruby in particular. I’m almost done with my final Object Oriented Ruby project – in fact – I’m in the process of turning it in. It’s definitely not finished though, like pretty much all software, but I’m looking forward to getting some much needed code review, and getting to work on some improvements.
Anyway, more about the project. It’s called monster_index. It’s a tool for playing Dungeons and Dragons, because I’m a nerd. Basically, you can run the program, and it will list a bunch of D&D monsters, and then you can go deeper and see a bunch of stats for each of those monsters. It’s all text-based, or rather, a ruby gem with a command line interface. So that means it’s a program you can download, install, run, and then use it through the terminal.
No, I didn’t take the time to gather all those monster stats myself. I’m not that obsessed with D&D, and that would take foreverrrrrr. I used a nice little tool called Nokogiri (a different, better ruby gem someone made) to look up all that info and sort out what I want, and embed it into my program. Lucky for me, this site exists, and Nokogiri, under my careful instruction, goes and grabs the info from it whenever monster_index needs it.
At this point, I’ve published the gem for public use (go nuts, everyone), and put the source code on GitHub, for all to see, and possibly collaborate with.
Like I said, It’s not totally finished yet – I mean what software ever is? But really, it’s lacking a huge number of monsters, because I need to learn to use Nokogiri better, and while I appreciate that site I mentioned earlier as a free resource, it’s not as neatly organized as I’d like it to be. Let’s get into the nitty gritty of that, because I bet you’re just on the edge of your seat, waiting to hear about this.
First thing my program does is create a bunch of instances of the Monster class, based on info it can get from the Scraper class. So the Scraper class uses Nokogiri to “scrape” information off of the pages of the site. First thing it looks at is this page. Easy enough to get a list of monsters from there – I’ll just get a copy of that page’s source code with this
|
1 |
doc <span class="pl-k">= </span><span class="pl-c1">Nokogiri</span>::<span class="pl-c1">HTML</span>(open(<span class="pl-s"><span class="pl-pds">"</span>http://www.d20srd.org/indexes/monsters.htm<span class="pl-pds">"</span></span>))
|
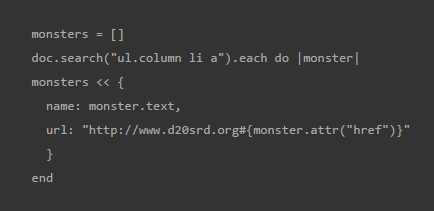
and then I can see they organize all the monsters into 4 columns with lists of monsters within lists of letters. basically. so I iterate through those and add all the monsters to an array like this
|
1
2
3
4
5
6
7
|
monsters = []
doc.search("ul.column li a").each do |monster|
monsters << {
name: monster.text,
url: "http://www.d20srd.org#{monster.attr("href")}"
}
end
|
so, perfect, now I’ve got all the types of monster, along with the urls to see their details. now I just have to go in and grab each one’s stats. that’s where I hit a road block, because their individual pages aren’t totally standardized (the horror)! so for a lot of them, this code works just fine
|
1
2
3
4
5
6
7
8
9
10
11
12
|
def self.scrape_monster_page(monster_url)
doc = Nokogiri::HTML(open(monster_url))
profile = {
size_type: doc.search("table tr td")[0].text,
hit_dice: doc.search("table tr td")[1].text,
initiative: doc.search("table tr td")[2].text,
speed: doc.search("table tr td")[3].text,
ac: doc.search("table tr td")[4].text,
attack: doc.search("table tr td")[7].text,
alignment: doc.search("table tr td")[19].text,
}
end
|
I go to that monster’s page, and grab each stat off of a table there. But then there’s a bunch of them that are organized differently. For example, “Archon.” That’s not an actual monster – it’s divided into Lantern, Trumpet, Hound, and Hound Hero types. And no, I actually don’t know what any of those are. I’ve never encountered them on my adventures through D&D. Anyway, that means I don’t want to list Archon after all, because there are no stats for that. Not only that, but those other sub-types don’t have their own pages – they all have different tables on the same page. And this happens with plenty of the monsters from the original list, except sometimes, inexplicably, not only will a page have tables for multiple monsters, but they also combined multiple tables into one more complex table. While I could probably work out some exceptions to my Nokogiri instructions, there seems to be too much inconsistency for me to bother scraping all those pages in different ways.
At some point, I’ll be both faster, and smarter about scraping pages, but for now, I just want to provide a quick reference on the simpler categories of monsters, without a bunch of weird sub-categories messing everything up. So I just added in a filter to basically ignore all the monsters where that was an issue, and finished up the rest of the gem, and published it. I ended up with wayyyy fewer monsters, it turns out (D&D is complicated), but still a pretty large number, and I’m happy with what I ended up with. So here we are! I’m now the author of a ruby gem.
lukeghenco
Good job. Your code looks great.